Configuration file¶
A configuration file generated by Kronos is a YAML file which describes a pipeline.
It contains all the parameters of all the components in the pipeline as well as the information that builds the flow of the pipeline.
A configuration file has the following major sections (shown in red ovals in the following figure):
where __TASK_i__ has the following subsections (shown in green ovals in the following figure):
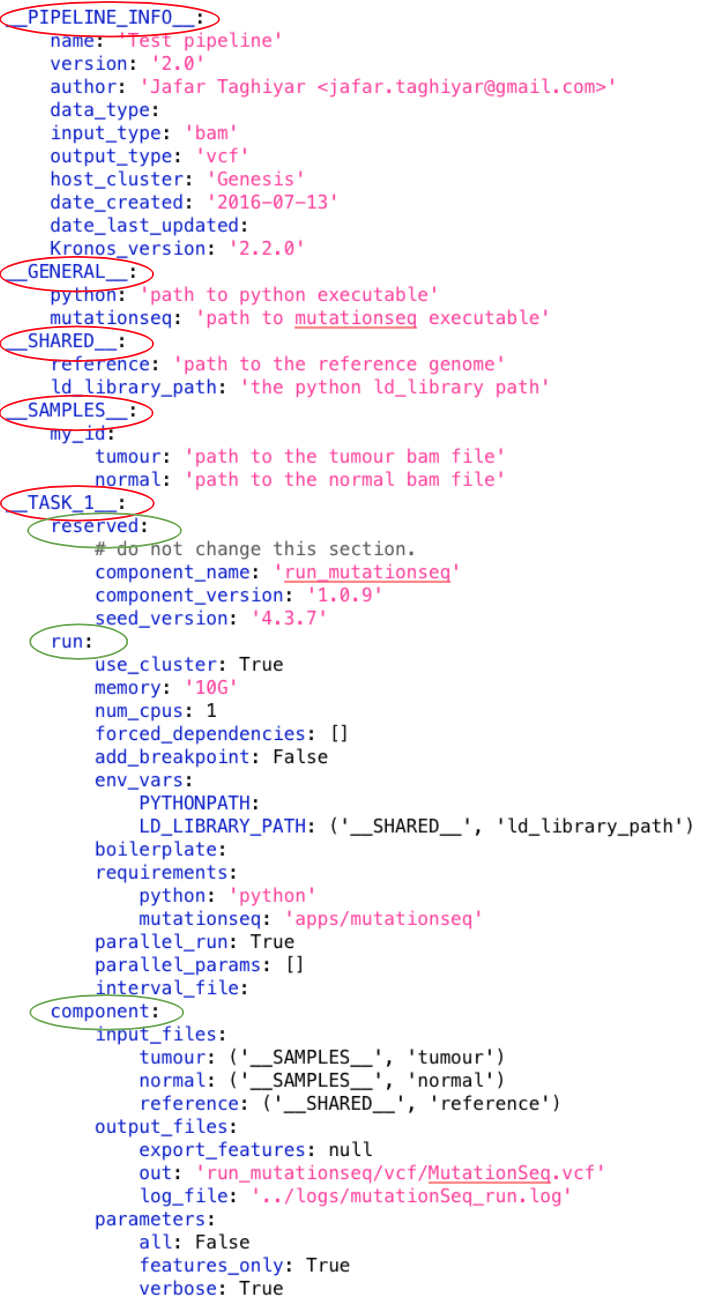
Pipeline_info section¶
The __PIPELINE_INFO__ section stores information about the pipeline itself and looks like the following:
__PIPELINE_INFO__:
name: null
version: null
author: null
data_type: null
input_type: null
output_type: null
host_cluster: null
date_created: null
date_last_updated: null
kronos_version: '2.0.0'
where:
name: a name for the pipelineversion: version of the pipelineauthor: name of the developer of the pipelinedata_type: this can be used for database purposesinput_type: type of the input files to the pipelineoutput_type: type of the output files of the pipelinehost_cluster: a name a cluster used to run the pipeline or ‘null’ if the pipeline is designed to run only locallydate_created: date that the pipeline is createddate_last_updated: last date that the pipeline is updatedkronos_version: version of thekronospackage that has generated the configuration file and is added automatically
Info
All these fields are merely informative and do not have any impacts on the flow of the pipeline.
General section¶
__GENERAL__ section contains key:value pairs derived automatically from the requirements field of the Component_reqs file of the components in the pipeline.
Each key corresponds to a particular requirement, e.g. Python, java, etc., and each value is the path to where the key is.
For instance, if there is python: /usr/bin/python entry in the requirements of a component in the pipeline, then you would have the following in the __GENERAL__ section:
__GENERAL__:
python: '/usr/bin/python'
Now, let assume there is another Python installations on your machine in /path/my_python/bin/python and you prefer to use this instead.
You can simply change the path to the desired one:
__GENERAL__:
python: '/path/my_python/bin/python'
Warning
This will overwrite the path of python installation specified in the requirements of ALL the components , hence the name GENERAL. If you want to change the path for only one specific task, then you should use the requirements entry in the run subsection of that task. Note that the task’s requirements entry takes precedence over the __GENERAL__ section.
Samples section¶
__SAMPLES__ section contains key:value pairs with a unique ID for each set of the pairs.
It enables users to run the same pipeline for different sets of input arguments at once, i.e. users can perform parameter sweep.
kronos will run the pipeline for all the sets simultaneously, i.e. in parallel mode.
For example, for the following configuration file, kronos will make two intermediate pipelines and runs them in parallel.
In one of the intermediate pipelines the values of tumour and normal parameters of __TASK_1__ are 'DAX1.bam' and 'DAXN1.bam', respectively, while in the other one they are 'DAX2.bam' and 'DAXN2.bam', respectively.
__SAMPLES__:
ID1:
tumour: 'DAX1.bam'
normal: 'DAXN1.bam'
ID2:
tumour: 'DAX2.bam'
normal: 'DAXN2.bam'
__TASK_1__:
component:
input_files:
tumour: ('__SAMPLES__', 'tumour')
normal: ('__SAMPLES__', 'normal')
The ID of each set of input arguments, e.g. ID1 or ID2, is used by kronos to create intermediate pipelines.
Warning
Each ID in the __SAMPLES__ section must be unique, otherwise their corresponding results will be overwritten.
Warning
kronos creates the following directories in the working directory to store the intermediate pipelines:
- intermediate_config_files
- intermediate_pipeline_scripts
Users should NOT modify them.
Tip
A connection to the __SAMPLES__ section, i.e. its first entry is __SAMPLES__, is called a sample connection.
The differences between __SAMPLES__ and __SHARED__ sections are:
- a unique ID is required in the
__SAMPLES__section for each set - a separate individual pipeline is generated for each set of
key:valuepairs, i.e. for each ID, in the__SAMPLES__section
Tip
The number of simultaneous parallel pipelines can be set by the user when running the pipeline using the input option -n.
Task section¶
Each task section in a configuration file corresponds to a component.
The name of a task section follows the convention __TASK_i__ where i is a number used to make the name unique, e.g. __TASK_1__ or __TASK_27__.
If a task is run in parallel then there will be sections with names __TASK_i_j__ which refer to the children of task __TASK_i__, e.g. __TASK_1_1__, __TASK_1_2__, etc.
Each task section has following subsections:
Reserved subsection¶
This subsection contains information about the component of the task:
reserved:
# do not change this section
component_name: 'name_of_component'
component_version: 'version_of_component'
seed_version: 'version_of_seed'
Warning
The information in this subsection should NOT be altered by users and are automatically specified by kronos.
Run subsection¶
This subsection is used to instruct the kronos how to run the task. It looks like the following example:
run:
use_cluster: False
memory: '5G'
num_cpus: 1
forced_dependencies: []
add_breakpoint: False
env_vars:
boilerplate:
requirements:
parallel_run: False
parallel_params: []
interval_file:
use_cluster¶
You can determine if each task in a pipeline should be run locally or on a cluster using the boolean flag use_cluster.
Therefore, in a single pipeline some tasks might be run locally while the others are submitted to a cluster.
Warning
If use_cluster: True, then pipeline should be run on a grid computer cluster.
Otherwise you’ll see the error message failed to load ClusterJobManager and pipeline would eventually fail.
Warning
If use_cluster: True, make sure you pass the correct path for the drmaa library specified by -d option (see Input options of run command for more information on input options).
The default value for -d option is $SGE_ROOT/lib/lx24-amd64/libdrmaa.so where SGE_ROOT environment variable is automatically added to the path, so you only need to specify the rest of the path if it is different than the default value.
memory¶
If you submit a task to a cluster, i.e. use_cluster: True, then memory specifies the maximum amount of memory requested by the task.
num_cpus¶
If you submit a task to a cluster, i.e. use_cluster: True, then num_cpus specifies the number of cores requested by the task.
forced_dependencies¶
You can force a task to wait for some other tasks to finish by simply passing the list of their names to the attribute forced_dependencies of the task.
For example, in the following config __TASK_1__ is forced to wait for __TASK_n__ and __TASK_m__ to finish running first.
__TASK_1__:
run:
forced_dependencies: [__TASK_n__, __TASK_m__]
Tip
forced_dependencies always expects a list, e.g. [], [__TASK_n__], [__TASK_n__, __TASK_m__].
Info
A dependency B for task A means that task A must wait for task B to finish first, then task A starts to run.
Info
If there is an IO connection between two tasks, then an implicit dependency is inferred by kronos.
add_breakpoint¶
A breakpoint forces a pipeline to pause.
If add_breakpoint: True for a task, pipeline will stop running after that task is done.
Once the pipeline is relaunched, it will resume running from where it left off.
This mechanism has a number of applications:
- if a part of a pipeline needs user’s supervision, for example to visually inspect some output data, then adding a breakpoint can pause the pipeline for the user to make sure everything is as desired and the relaunch from that points.
- you can run a part of a pipeline several times, for example to fine tune some of the input arguments. This can happen by adding breakpoint to the start and end tasks for that part of the pipeline and relaunch the pipeline every time.
- you can run different parts of a single pipeline on different machines or clusters provided that the pipeline can access the files generated by the previous runs. For instance, you can run a pipeline locally up to some point (a breakpoint) and then relaunch the pipeline on a different machine or cluster to finish the rest of the tasks.
Tip
If a task is parallelized and it has add_breakpoint: True, then the pipeline waits for all the children of the task to finish running and then applies the breakpoint.
Note
When a breakpoint happens, all the running tasks are aborted.
env_var¶
You can specify a list of the environment variables, required for a task to run successfully, directly in the configuration file. It looks like the following:
__TASK_n__:
run:
env_vars:
var1: value1
var2: value2
Tip
If an environment variable accepts a list of values, you can pass a list to that environment variable. For example:
env_vars:
var1: [value1, value2, ...]
boilerplate¶
Using this attribute you can insert a command or an script, or in general a boilerplate, directly into a task. The boilerplate is run prior to running the task. For example, assume you need to setup your python path using load module command. You can either pass the command as follows:
__TASK_n__:
run:
boilerplate: 'load module python/2.7.6'
or save it in a file e.g. called setup_file:
load module python/2.7.6
and pass the path to the file, e.g. /path/to/setup_file, to the boilerplate attribute:
__TASK_n__:
run:
boilerplate: /path/to/setup_file
requirements¶
Similar to the __GENERAL__ section, this entry contains a list of key:value pairs derived automatically from the requirements field of the Component_reqs file of the component. The difference is that this list contains only the requirements for this task and applies only to this task and not the rest of the tasks in the pipeline.
It looks like the following:
__TASK_n__:
run:
requirements:
req1: value1
req2: value2
Tip
This entry takes precedence over the __GENERAL__ section. If you want to get the values for the requirements from the __GENERAL__ section, then simply leave the value for each requirements in this entry blank or pass null.
For example:
requirements:
req1:
req2:
parallel_run¶
It is a boolean flag that specifies whether or not to run a task in parallel.
If parallel_run: True, the task is automatically expanded to a number of children tasks that are run in parallel simultaneously.
Warning
A task needs to be parallelizable to run in parallel.
Tip
If a task is not parallelizable, the attributes parallel_run, parallel_params and interval_file will NOT be shown in the run subsection and the following message is shown in the configuration file under the run subsection of the task:
NOTE: component cannot run in parallel mode.
Otherwise it is considered parallelizable.
There are two mechanisms a task is parallelized:
parallelization
In this mechanism, the task is expanded to its children where the number of its children is determined by one of the following:
- number of lines in the interval_file
- number of chromosomes, if there is no interval file specified
Tip
kronos uses the set [1, 2,..., 22, X, Y] for chromosome names and it parallelizes a task based on this set by default if no interval file is specified.
synchronization
If a task has:
- an IO connection to a second task
- and, the parallel_params is also set
then kronos expands the first task as many times as the number of the children of the second task, if the two tasks are synchronizable.
Tip
Two tasks are synchronizable if:
- both are parallelizable, and
- if they are both parallelized, they have the same number of children, and
Note
If any of the conditions mentioned above does not hold true, then kronos automatically merges the results from the predecessor task and passes the result to the next task.
Tip
If task A is synchronizable with both tasks B and C individually but not simultaneously, then kronos synchronizes task A with one of them and uses the merge for the other one.
parallel_params¶
This attribute controls:
- whether to synchronize a task with its predecessor(s)
- over what parameters the synchronization should happen
It accepts a list of parameters of the task that have IO connection to the predecessors.
For instance, if task __TASK_n__ has task __TASK_m__ as its predecessor and has two IO connections with it, e.g. in_param1: (__TASK_m__, 'out_param1') and in_param2: (__TASK_m__, 'out_param2').
Assuming that the two tasks are synchronizable, parallel_params = ['in_param1'] forces the kronos to synchronize the task __TASK_n__ to task __TASK_m__ over the parameter in_param1.
In other words, task __TASK_n__ is expanded as many time as the number of the children of task __TASK_m__ and each of its children gets its value for in_param1 from the out_param1 of one of the children of task __TASK_m__.
interval_file¶
An interval file contains a list of intervals or chunks which a task will use as input arguments for its children. For example if an interval file looks like:
chunk1
chunk2
chunk3
then each line, i.e. chunk1, chunk2, chunk3, will be passed separately to a children as an input argument.
The path to the interval file is passed to the interval_file attribute.
Warning
If you want to use the interval file functionality in a task, the component of that task should support it. In other words, it should have the focus method in its component_main module. This method determines how and to which parameter a chunk should be passed.
Component subsection¶
This subsection contains all the input parameters of the component of the task. The parameters are categorized into three subsections:
input_files: lists all the input files and directoriesoutput_files: lists all the output files and directoriesparameters: lists all the other parameters
More on the configuration file¶
configuration file flags¶
kronos uses the following flags assigned to various parameters of different tasks:
__REQUIRED__: means that the user MUST specify value for that parameter.__FLAG__: means that the parameter is a boolean flag. Users can assignTrueorFalsevalues to the parameter. The default value isFalse.
Tip
The default values for the parameters appear in the configuration file. If there is no default value, then either one of the configuration file flags will be used or it is left blank.
Note
Put quotation marks around string values, for example ‘GRCh37.66’. Unquoted strings, while accepted by YAML can result in unexpected behaviour.
configuration file keywords¶
You can use the following keywords in the configuration file which will be automatically replaced by proper values at runtime:
| Keyword | Description |
|---|---|
$pipeline_name |
the name of the pipeline |
$pipeline_working_dir |
the path to the working directory |
$run_id |
run ID |
$sample_id |
the ID used in the samples section |
Warning
The character $ is part of the keyword and MUST be used.
configuration file reserved keywords¶
The following words are reserved for the kronos package:
- reserved
- run
- component
Warning
The reserved keywords can NOT be used as the name of parameters of components/tasks.
Output directory customization¶
kronos supports paths in the output_files subsection of the component subsection.
In other words, user can specify paths like /dir1/dir2/dir3/my.file to the parameters of the output_files subsection and all the directories in the path will be automatically made if they do not exist.
For example, kronos will make directories dir1, dir2, dir3 with the given hierarchy.
This mechanism enables developers to make any directory structure as desired.
Basically, they can organize the outputs directory of their pipeline directly from within the configuration file.
For instance, assume a pipeline has two tasks with components comp1 and comp2.
The user can categorize the outputs of these tasks by the names of their corresponding components as follows (note the values assigned to out and log parameters of each component):
__TASK_i__:
component:
output_files:
out: comp1/res/my_res_name.file
log: comp1/log/my_log_name.log
__TASK_ii__:
component:
output_files:
out: comp2/res/my_res_name.file
log: comp2/log/my_log_name.log
so, the following tree is made inside the outputs directory given the above configuration file:
outputs
|____comp1
| |____log
| | |TASK_i_my_log_name.log
| |____res
| |TASK_i_my_res_name.file
|____comp2
|____log
| |TASK_ii_my_log_name.log
|____res
|TASK_ii_my_res_name.file
Tip
Output filenames are always prepended by the task names to prevent overwriting, e.g. TASK_i and TASK_ii in the above example.
Tip
If you want to specify a directory name to a parameter, you can do so by using / character at the end of the directory name.
This instructs kronos to make the directory in the outputs directory or any other specified path if the direcotry does not exist.